一、crab简介
这个寒假,翻了翻《集体智慧编程》这本书的前几章。第2章讲的就是推荐系统,觉得挺有意思的。然后上网搜了搜有关python的推荐系统,在推荐系统开源软件列表汇总和点评这篇文章,看了关于python推荐系统的两个开源项目,是crab和python-recsys。于是安装试用了一下crab。
Crab是基于Python开发的开源推荐软件,其中实现有item和user的协同过滤。据说更多算法还在开发中,
Crab的python代码看上去很清晰明了,适合一读
二、安装crab
crab官网有相关的安装说明。需要提醒的是,我按照官网的说明,可以安装成功,但是该模块会有一些函数和方法导入不进去。后来,发现,正确的安装方法应该是,先在这里下载crab源码,用python setup.py install的方法安装,然后再使用pip install -U crab或者easy_install -U crab的方法升级该源码。
三、快速试用crab
crab官方文档目前只有一个Introducing Recommendation Engines可以浏览,文档还有待建设。
下面就按照这个介绍进行,先导入数据集:
from scikits.crab import datasets movies = datasets.load_sample_movies() songs = datasets.load_sample_songs()
我们可以在模块目录下打开该示例数据集(sample_movies.csv):
Jack Matthews;Lady in the Water;3.0 Jack Matthews;Snakes on a Planet;4.0 Jack Matthews;You, Me and Dupree;3.5 Jack Matthews;Superman Returns;5.0 Jack Matthews;The Night Listener;3.0 Mick LaSalle;Lady in the Water;3.0 Mick LaSalle;Snakes on a Planet;4.0 Mick LaSalle;Just My Luck;2.0 Mick LaSalle;Superman Returns;3.0 Mick LaSalle;You, Me and Dupree;2.0 Mick LaSalle;The Night Listener;3.0 Claudia Puig;Snakes on a Planet;3.5 Claudia Puig;Just My Luck;3.0 Claudia Puig;You, Me and Dupree;2.5 Claudia Puig;Superman Returns;4.0 Claudia Puig;The Night Listener;4.5 Lisa Rose;Lady in the Water;2.5 Lisa Rose;Snakes on a Planet;3.5 Lisa Rose;Just My Luck;3.0 Lisa Rose;Superman Returns;3.5 Lisa Rose;The Night Listener;3.0 Lisa Rose;You, Me and Dupree;2.5 Toby;Snakes on a Planet;4.5 Toby;Superman Returns;4.0 Toby;You, Me and Dupree;1.0 Gene Seymour;Lady in the Water;3.0 Gene Seymour;Snakes on a Planet;3.5 Gene Seymour;Just My Luck;1.5 Gene Seymour;Superman Returns;5.0 Gene Seymour;You, Me and Dupree;3.5 Gene Seymour;The Night Listener;3.0 Michael Phillips;Lady in the Water;2.5 Michael Phillips;Snakes on a Planet;3.0 Michael Phillips;Superman Returns;3.5 Michael Phillips;The Night Listener;4.0
该文件每行通过分号被分成三列。第一列是用户名;第二列是电影名;第三列是评分。相信看过《集体智慧编程》的同学对这样的示例数据很眼熟吧。我们也可以用这个格式来构造自己的数据集。
将movies.data打印出来可以看到这样的结果:
>>> print movies.data
{1: {1: 3.0, 2: 4.0, 3: 3.5, 4: 5.0, 5: 3.0},
2: {1: 3.0, 2: 4.0, 3: 2.0, 4: 3.0, 5: 3.0, 6: 2.0},
3: {2: 3.5, 3: 2.5, 4: 4.0, 5: 4.5, 6: 3.0},
4: {1: 2.5, 2: 3.5, 3: 2.5, 4: 3.5, 5: 3.0, 6: 3.0},
5: {2: 4.5, 3: 1.0, 4: 4.0},
6: {1: 3.0, 2: 3.5, 3: 3.5, 4: 5.0, 5: 3.0, 6: 1.5},
7: {1: 2.5, 2: 3.0, 4: 3.5, 5: 4.0}}打印结果是一个字典。最外面的一层数字1-6是用户id。每个用户id对应了该用户所评分的对应,如:用户1,的第一部电影1对应的评分是3分。当然接下来我们可以打印出用户id列表和电影id列表,方便查看:
>>> print movies.user_ids
{1: 'Jack Matthews',
2: 'Mick LaSalle',
3: 'Claudia Puig',
4: 'Lisa Rose',
5: 'Toby',
6: 'Gene Seymour',
7: 'Michael Phillips'}
>>>
>>> print movies.item_ids
{1: 'Lady in the Water',
2: 'Snakes on a Planet',
3: 'You, Me and Dupree',
4: 'Superman Returns',
5: 'The Night Listener',
6: 'Just My Luck'}可以看到,用户1就是Jack Matthews,电影就是Lady in the water。
下面建立movies的模型:
>>> from scikits.crab.models import MatrixPreferenceDataModel >>> #Build the model >>> model = MatrixPreferenceDataModel(movies.data)
接下来,导入皮尔逊相关度和用户相似度,建立起相似度模型:
>>> from scikits.crab.metrics import pearson_correlation >>> from scikits.crab.similarities import UserSimilarity >>> #Build the similarity >>> similarity = UserSimilarity(model, pearson_correlation)
这里基于用户模型的函数参数设置为:similarity = UserSimilarity(数据模型,相似度模型)
最后,使用基于用户推荐的方法,就可以输出为用户5(Toby)的影片推荐了三部电影:
from crab.recommenders.knn import UserBasedRecommender >>> #Build the User based recommender >>> recommender = UserBasedRecommender(model, similarity, with_preference=True) >>> #Recommend items for the user 5 (Toby) >>> recommender.recommend(5) [(5, 3.3477895267131013), (1, 2.8572508984333034), (6, 2.4473604699719846)]
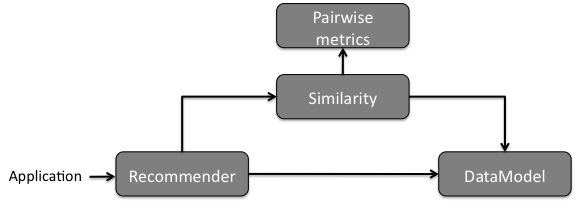
这个推荐系统的架构,是这样的:
怎么算是crab安装成功啊
import 一下就知道了啊